
Blog
Sabrina: seven-file B2B prospecting
Case study: from a dense PDF pipeline (Discord, LinkedIn, Unipile, Lusha, Odoo) to seven markdown files the agent can run inside—filing tiers, deduplicating nine first-draft overlaps, and writing SOUL from what the spec never said out loud.
A walkthrough of every decision along the way — what went where, what broke in the first draft, and what the spec alone could not tell us.
Sabrina is being built for a commercial team that needs qualified B2B leads in Odoo without manually chaining LinkedIn search, enrichment, and CRM updates after every command.
The brief
The starting point was a thorough functional specification for the pipeline below — six phases, decision tables, error handling, rate limits, deduplication rules, field mappings. Everything you would want before writing a line of code.
The full pipeline in one line:
Discord command → LinkedIn search (Unipile) → contact enrichment (Lusha) → Odoo CRM registration → LinkedIn connection request → Discord summary.
The job was not to build the pipeline. It was to translate it into seven files that the agent could actually live inside — and to think carefully about what belongs where.
Step one: reading the spec as a filing problem
The first instinct when faced with a detailed spec is to start writing files immediately. That was a mistake. The first draft was produced too fast, with content placed by feel rather than by principle — and it showed.
Instead of starting over blindly, the right move was to step back and ask a different question about each section of the spec: what kind of information is this?
There are roughly four kinds of information in any agent specification. They map to tiers. And the tiers have a direction: lower tiers are read by higher ones, never the other way around.
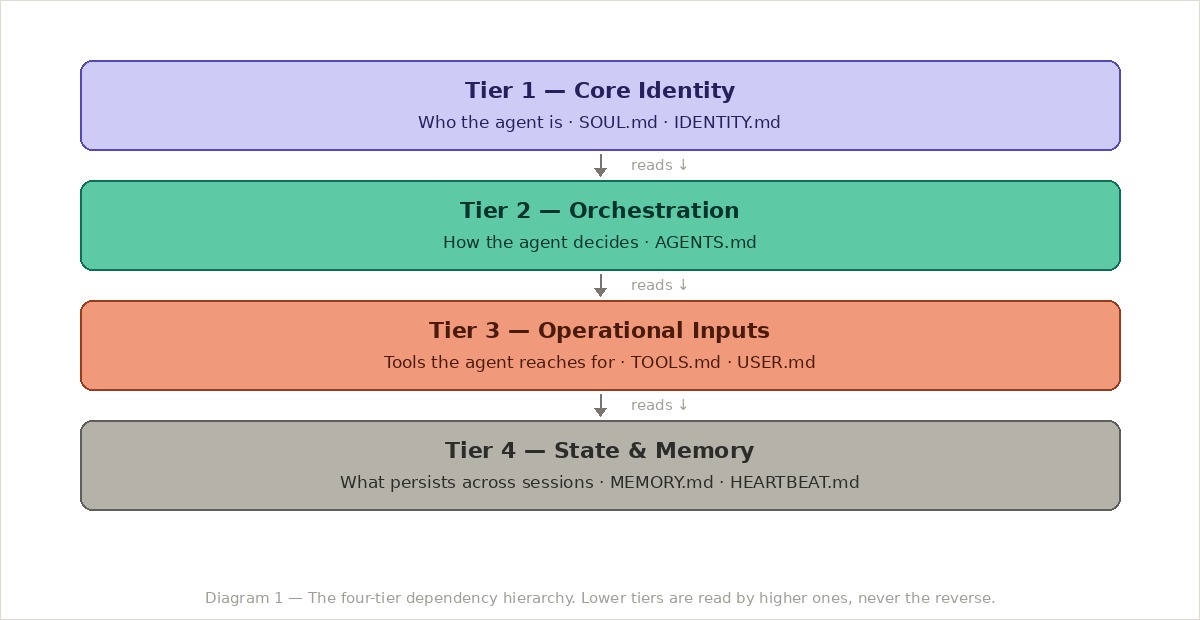
With this mental model, each section of the specification gets tagged: is this identity? orchestration? operational? or state? That exercise alone makes most of the filing decisions obvious — but it has to happen before writing, not after.
Step two: the seven files — what actually went where
Here is what the spec revealed immediately: the specification was almost entirely operational. Very little of it was about who Sabrina is — most of it was about what Sabrina does.
That is a common pattern in agent design. The identity layer gets neglected because it feels soft. But it is the identity layer that governs behaviour when the pipeline does not give a clear answer.
| File | What lives there |
|---|---|
SOUL.md | Voice, values, hard limits. The five principles Sabrina applies when no rule resolves the situation. |
IDENTITY.md | Metadata and routing. Model config, session settings, integration map. The only place credentials are referenced by name. |
AGENTS.md | The conductor. Session boot order, the six-phase pipeline as executable pseudocode, decision rules table, escalation paths. |
USER.md | Two user profiles: commercial and admin. Onboarding checklist, every command, every message the commercial can receive. |
MEMORY.md | Evergreen facts. Confirmed pipeline rules, Odoo configuration, known operational patterns, credentials references. |
HEARTBEAT.md | Scheduled tasks. API health checks every 15 minutes during active Jobs. Daily rate-limit resets. Weekly lead summaries. |
TOOLS.md | Complete database schema, every API tool with parameters and error handling, the Lusha enrichment decision tree. |
TOOLS.md is the largest and most specific file. It is the only file that changes if an API endpoint changes.
Step three: the first draft had nine duplicates
Here is what the first draft actually looked like: nine areas of duplicated content. Five were exact copies of the same information in two files. Four were partial overlaps where the same rule appeared at different levels of detail.
This was not caught until reading all seven files side by side — something that sounds obvious but is easy to skip when you are writing file by file. The duplicates were invisible until you looked at the whole picture at once.
The most glaring example was the LinkedIn rate limit. It appeared in four places:
- In
MEMORY.mdas a rule: "20 invitations/day/account" - In
SOUL.mdas a principle: "protect the commercial's LinkedIn account" - In
TOOLS.mdas implementation: "queue if exceeded, abort if account restricted" - In
HEARTBEAT.mdas a monitoring task: "alert at 75%, stop at 100%"
At first glance this looks reasonable — each file adds a different perspective. But the number 20 appeared verbatim in three of those files. If that limit changes, you need to remember to update three separate files. That is how agents start behaving in contradictory ways in production.
The fix was to give each file a single voice and a single ownership:
- MEMORY.md owns what the rule is (the number: 20 invitations/day)
- TOOLS.md owns how it is implemented (queue, abort, notify)
- SOUL.md owns why it matters (the principle, not the number)
- HEARTBEAT.md owns when to act on it (75% and 100% thresholds)
After deduplication, the number 20 appears in exactly one file. The others reference the concept without repeating the value.
The database schema had the same problem. It appeared partially in MEMORY.md, partially in TOOLS.md, and was referenced in AGENTS.md. After the audit, the complete schema lives only in TOOLS.md. Every other file that needs to reference a table names it without reproducing its structure.
Duplicates are not just redundant. They are the symptom of unclear ownership. Every duplicate found during this process was evidence of a decision that had not been made yet about which file owns that piece of information.
Step four: the pipeline as AGENTS.md
The most important single file is AGENTS.md. It is where the six-phase pipeline becomes something the model can actually execute — not prose describing the process, but structured pseudocode with explicit loop conditions, decision branches, and escalation points.
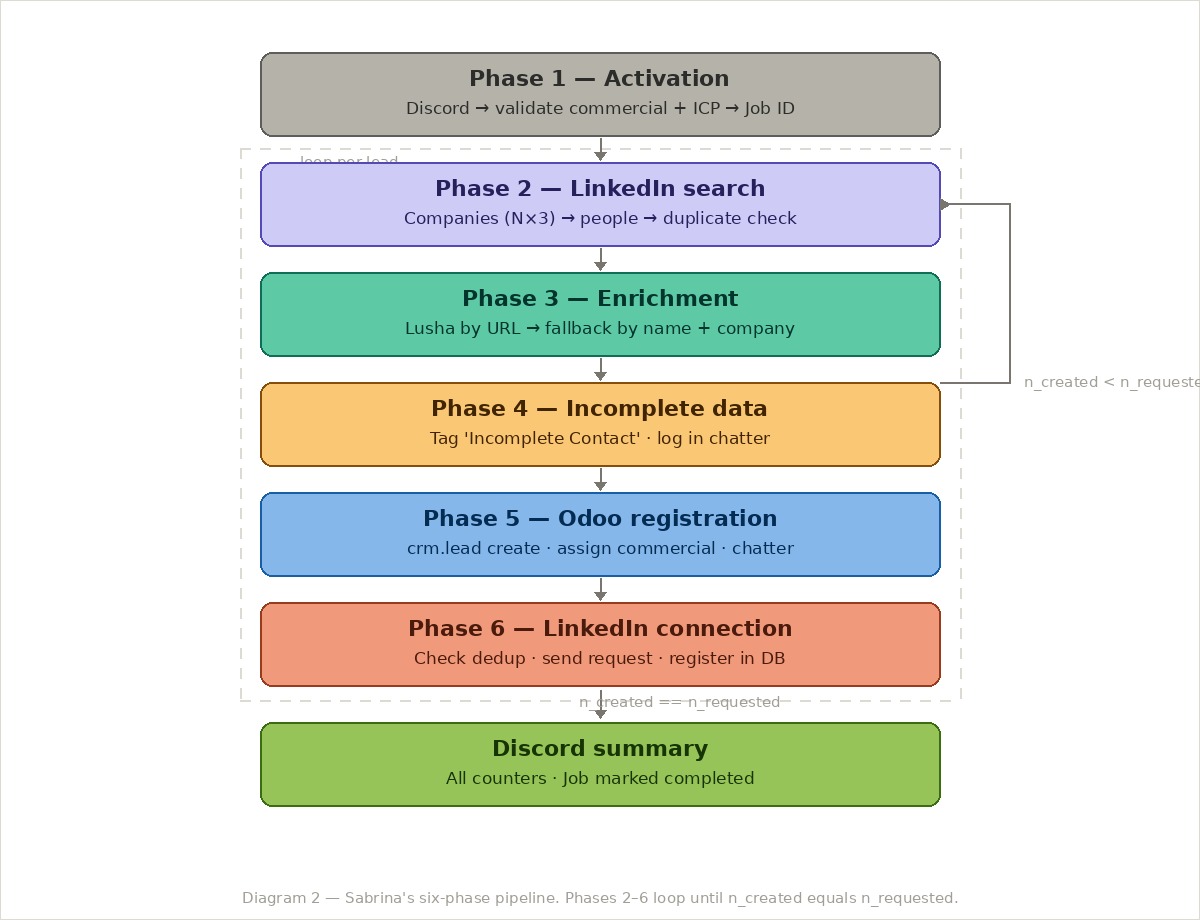
The key insight in AGENTS.md is the loop condition. The agent does not just run the pipeline once — it loops through companies, processing one lead per company, until it reaches the requested number. The Job Coordinator tracks five counters: created, incomplete, discarded, connections sent, and the target N. The loop is deterministic and stops cleanly.
The loop check is a single line:
n_created == n_requested?
NO → loop to next company (Phase 2)
YES → Discord summary
Simple. But without it written explicitly, the model has to infer the stopping condition from prose — and prose is ambiguous.
Step five: the decision rules table
The specification had many implied decisions buried in prose. Situations where the pipeline did not give a clear answer.
- What do you do if Lusha returns a generic email?
- What if a company is already in Odoo as a lead but not an active client?
- What if the LinkedIn rate limit is hit halfway through a Job?
These were extracted into a single decision table in AGENTS.md. Not because the table is more readable — it is not — but because an explicit table is something the model can actually apply. Prose requires interpretation. A table requires lookup.
| If | Then |
|---|---|
| Generic email returned (info@, contact@…) | Treat as not found. Retry by name + company. If still generic → Incomplete Contact. |
| Company in Odoo as lead (not active client) | Do not exclude the company. Check if the specific person already exists. |
| Prior LinkedIn invitation to same user ID | Skip. Log "duplicate avoided". Do not count as sent. Continue. |
| Rate limit 100% (20/20) | Stop invitations. Notify. Queue for next day. Leads stay in Odoo. |
| Fewer than N companies found after ×4 search | Create what was found. State the gap. Suggest broadening ICP in summary. |
| Conflicting instructions | SOUL.md limits → AGENTS.md rules → user request. |
| Unknown situation | Acknowledge. Do not guess. Notify commercial and wait. |
The "company already in Odoo as a lead" case is a good example of a decision that was not obvious. The naive implementation would exclude any company already in the system. The right implementation is more nuanced: exclude active clients (they are already customers), but a company that is just a lead from a previous Job should not block a new search for a different person at that company. That distinction took a full iteration to land on.
Step six: SOUL.md had to be written from scratch
This was the hardest part. After mapping all the spec content to files, SOUL.md was essentially empty. The specification covered everything the agent does but said almost nothing about who the agent is.
The first attempt at SOUL.md was a list of rules that belonged in AGENTS.md. It was scrapped entirely and rewritten from a different starting point: not "what does the spec say?" but "what would this agent do when the spec runs out?"
That is the right question for SOUL.md. Not rules — principles. Rules live in AGENTS.md. Principles are what the agent reaches for when there is no rule that covers the situation.
For Sabrina, five emerged by going through every ambiguous scenario in the spec and asking what value judgement the agent would need to make:
1. Quality over volume. Never relax a validation rule to reach the requested number of leads. Four complete leads beat ten incomplete ones.
2. Full traceability. Every lead in Odoo must be traceable to its Job, its commercial, and the completeness of its data. If it cannot be traced, it does not ship.
3. Protect the LinkedIn accounts. The rate limit is not a guideline. It is a ceiling that protects the commercial's personal LinkedIn account from restriction.
4. Validate, do not assume. Missing ICP field? Ask. Unknown commercial? Abort. The cost of starting wrong is always higher than the cost of asking first.
5. Never block a Job on a single lead. If Lusha fails, mark and move on. If an API errors, retry twice and move on. The Job continues unless the infrastructure is completely down.
None of these appear in the original specification. They are derived from reading what the spec implicitly assumes the agent will do when things go wrong.
Step seven: Lusha enrichment — the decision tree that matters most
The Lusha enrichment logic is the most consequential decision in the pipeline. If it fails, the lead still gets created — but without contact data it is significantly less useful.
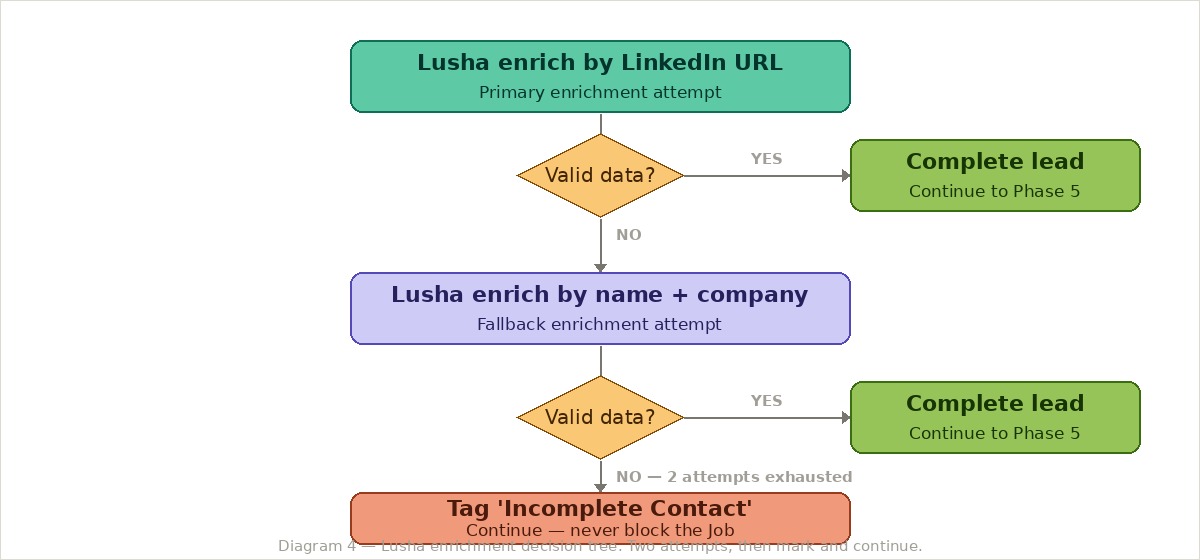
The critical design decision: always create the lead, even if both enrichment attempts fail. Never block the Job. Mark the lead, log the reason, and let the commercial decide what to do with it. This sounds obvious written down, but the first version of the spec implied stopping the Job if enrichment failed completely — which would mean losing all the work done to find and validate that lead.
Step eight: HEARTBEAT.md — the agent that runs without being asked
The heartbeat was the most interesting file to design. The specification describes Sabrina as an on-demand agent — the commercial asks, Sabrina delivers. But a real production agent needs to do things without being asked: monitor API health, enforce rate limits, detect stalled Jobs, validate credentials on startup.

The most important rule in HEARTBEAT.md is the autonomy limit: the heartbeat never takes destructive or irreversible actions without explicit confirmation. It monitors, alerts, and queues. It does not delete, does not send, does not modify. If it detects a problem, it notifies and waits.
The startup validation is equally important: before accepting any Job, Sabrina validates all four credentials (Discord, Unipile, Lusha, Odoo). A failed credential means no Jobs — not a degraded mode, not a retry loop, not a silent failure.
Step nine: where does the database schema live?
One decision cost more iterations than any other: where does the agent's internal database schema belong?
The schema defines five tables: commercials mapping, ICP templates, jobs, processed leads, and LinkedIn invitations. It is referenced by almost every tool in TOOLS.md and by the session loop in AGENTS.md. The first instinct was to put it in MEMORY.md — it felt like "something the agent needs to know". But MEMORY.md is for evergreen facts that change rarely, not for technical specifications.
The second attempt was to split it: put the table names in MEMORY.md and the full column definitions in TOOLS.md. That created the exact duplication problem described earlier.
The right answer — which took three iterations to land on — is that the complete schema belongs entirely in TOOLS.md, because it is the file that describes what the agent can reach for and how. MEMORY.md references the table names where needed, without reproducing any column definitions. AGENTS.md references the table names in the pipeline logic, also without reproducing structure.
The rule that emerged from this: if a piece of information changes together with something else, it belongs in the same file as that something else. The schema changes when the tools change. So the schema lives with the tools.
What we learned
The filing problem is the design problem. Where you put a piece of information is a decision about who owns it, when it changes, and what happens when it conflicts with something else. Getting the filing right forces you to think clearly about the agent's responsibilities — and you cannot do that by writing file by file without stepping back.
Read all seven files together before calling the first draft done. The duplicates were invisible until the files were read as a set. Writing file by file creates blind spots. The audit pass — reading all seven looking specifically for the same information in multiple places — is not optional.
SOUL.md cannot be written from the spec. It has to be written from the gaps in the spec. The question is not "what does the spec say?" but "what would this agent do when the spec runs out?" That is a different kind of reading, and it requires a separate pass.
The hardest decisions are not technical. The database schema question, the Lusha fallback behaviour, the deduplication rules for companies — none of these required complex logic. They required making a choice and owning it. The spec leaves many of these choices implicit. Making them explicit is the actual work.
The heartbeat earns its file. It is tempting to skip HEARTBEAT.md for simple agents. But any agent that touches rate-limited external APIs, writes to a production CRM, and runs unattended needs autonomous health monitoring. The heartbeat is what separates a demo from a production deployment.
The seven-file spec works because it forces you to have these conversations before the code is written. The files are not documentation of what was built — they are the specification of how the agent thinks.
What comes next
These files are now going into real use. When the team starts running live prospecting Jobs, Sabrina will process real leads with real LinkedIn accounts — that is when the spec meets reality. The follow-up will be a before/after of the seven files: what changed after the first production runs, which rules needed updating, and which decisions turned out to be wrong — grounded in a commercial team at work, not a hypothetical walkthrough. That post will ship once there is enough real data to make it worth reading.
The seven-file framework is documented and free to fork at build-your-agents.vercel.app. The spec, templates, and session loop reference are all public.