
Blog
Odín: the case that made everything click
Origin story: four months configuring a CRM for a client, one honest question about knowledge transfer, and five minutes that replaced one full day of bulk configuration work. This is what pushed me to study agentic AI seriously.
Not a lab experiment, not a proof of concept. A real client, a real constraint, and the right question asked at the right moment.
Four months inside a CRM
The starting point was as ordinary as they come: a client, a CRM we were customising for them, and the need to automate processes that were consuming time nobody had.
I spent roughly four months learning that CRM properly—its logic, its limits, its shortcuts, its edge cases. Not learning to use it: learning why it worked the way it did, what each configuration decision implied downstream, and how to map its technical possibilities onto the client's actual requirements.
By the end of that period I had something valuable: a precise mental model of how the whole system held together. I knew what to touch, in what order, what any given adjustment would cost or unlock. The kind of tacit knowledge that normally lives in one person's head—and forces everyone else to start from scratch whenever that person is unavailable.
Two observations surfaced that, at the time, seemed unrelated:
- That accumulated knowledge needed to live somewhere structured and reusable.
- The same knowledge could serve future projects without repeating the same learning curve.
I did not yet know how to connect those two things. But the question had been asked.
The question that changed the framing
The project eventually reached a phase that required high-complexity, highly-specific changes. Changes that were straightforward in principle but depended on a layer of context only I had internalised. That is when I asked what seemed like a straightforward team-management question—but turned out to be something else entirely:
"If I am not here, can someone else do this? Probably yes—but how long will they spend learning what I already know? They would need to understand the CRM, how I have been configuring it, how it works internally, and also the specific way this particular client needs it done. Does someone have to lose that time again?"
The honest answer was: no. That road had already been travelled. All of that knowledge could—and should—be available in a different form. Not locked in my head, not scattered across notes that someone else would have to decode. Active, queryable, ready to apply.
That reasoning is what led us to build Odín.
What Odín was supposed to do
The idea was straightforward to state, harder to execute: transfer everything learned over those four months into an AI agent that could operate with that knowledge autonomously. Not a passive knowledge base to consult. A system that could execute real tasks using that context.
Looking back, three things determined how well it worked — or didn't:
- Transferred knowledge — the CRM's logic, the client's requirements, the configuration patterns accumulated over four months, structured in a way the model could use.
- A clear specification — explicit instructions for what the agent should do, in what order, and with what quality criteria. Not just "here is what I know"—here is exactly what you need to do with it.
- Defined limits — the operational boundaries within which the agent was allowed to act. Not restrictions imposed after the fact. Guardrails designed alongside the task, as part of the design.
We did not start with all three in place. We learned their weight by experiencing what happened when each one was missing.
How we actually built it
The honest version: we built it the old-school way.
No structured files, no tiered architecture, no separation between identity and operational context. We sat down with the agent and told it what it needed to know as we went. You have access to this. You can modify this. You can load this. Every time it completed a step we told it to save what it had just done to memory. It was, essentially, a running session journal dressed up as an agent.


The recurring pattern: complete a step, save it to memory. Session after session, the same reflex. It worked — until it didn't.
It worked. That was the surprising part. The knowledge was there—scattered across memory entries and session notes rather than organised in any principled way—but it was there. The agent could find it and use it. Badly structured context still beats no context.
What we did not realise at the time was that we were accumulating technical debt inside the agent. Every new task added another memory entry. There was no ownership model—the same piece of information might appear three times in slightly different forms. There were no guardrails, no defined scope, no explicit stopping conditions. The agent would do what we asked, but we were never entirely sure it would do exactly that and nothing else.
That messy first version is what produced the five-minute result. And it is also what made it clear that the approach did not scale. Odín worked because the task was contained and we were watching closely. It would not have survived a more complex brief, a longer run, or a session we were not present for. Correcting those problems—properly—is what eventually led to the way we build agents now.
Five minutes instead of one day
And yet — it worked.
With no prior depth in agentic development—configuring largely by instinct, learning as we went, carrying more questions than certainties—in under a week Odín was completing in five minutes what had previously taken one full working day: bulk data loading, field mapping, label configuration, automation flows. The kind of CRM configuration work that is not technically complex but is slow, detail-heavy, and entirely dependent on knowing exactly how this particular client's setup was structured.
This was not a demo that ran once and could not be reproduced. It was the result of depositing the right knowledge, specifying the task clearly, and containing the agent's scope precisely enough to trust it. Three things that, combined, produced something reliable.
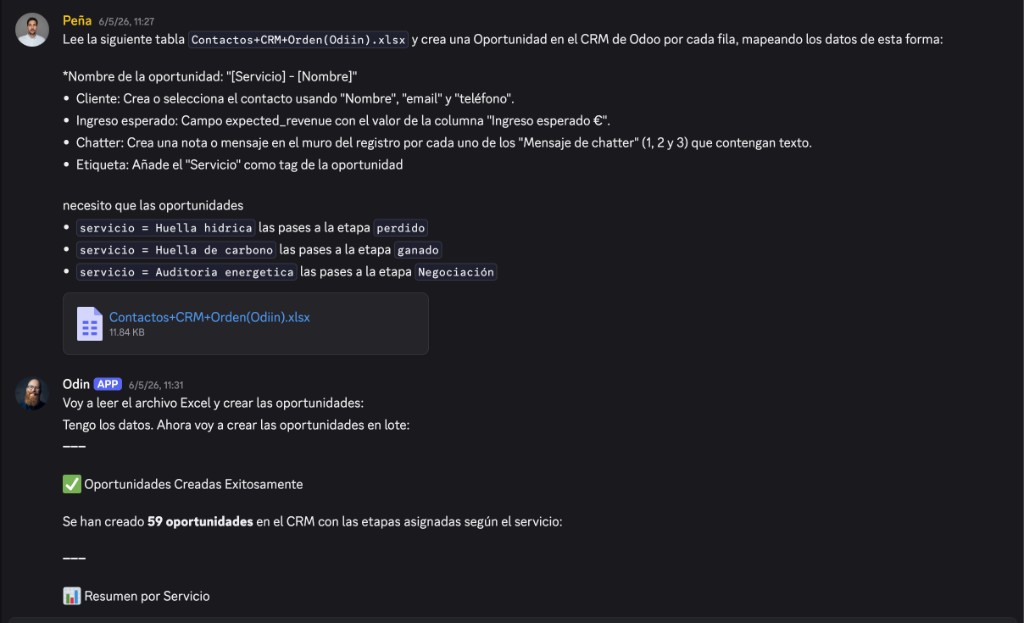
Odín processing a 59-row Excel file and creating one CRM opportunity per row, with stages assigned by service type — from a single Discord message.
The first time we watched it execute in real time what would have taken a full day, there was a moment of silence. The kind that means something has shifted.
What the process taught us
The Odín build was brief. The lessons were not.
Accumulated knowledge can be transferred—and an agent can work with it. The four months of CRM configuration were not wasted when we handed the work to an agent. The field dependencies, the label hierarchies, the flow logic — all of it had been described to Odín in scattered session notes, but it was there. The agent could retrieve it and act on it. That was the first proof that the learning curve does not have to be walked twice.
Knowledge alone is not enough—it needs a specification. Early on, we gave Odín access to everything and told it to load the data. Without a clear order of operations, it would occasionally apply labels before the relevant fields existed, or configure flows that referenced contacts that had not been imported yet. The knowledge was correct. The sequence was not. Adding an explicit step order — field creation first, then data load, then labels, then flows — was what made the output reliable.
Limits are part of the design, not an afterthought. We asked Odín to configure a set of labels. It configured them — and then started applying them to existing records it inferred should have them. That inference was not wrong. But it was not asked for, and it changed data we had not reviewed. Without a "do not act beyond the explicit task" boundary, the agent was helpful in ways we had not authorised. Guardrails are not restrictions that reduce what the agent can do. They are the condition that makes it possible to trust what it does.
You have to verify, not assume. Because we were building Odín's context in real time — telling it to save each completed step to memory — we had no way to know, session to session, whether what it had stored was accurate. We would start a new session, ask Odín to continue, and occasionally find that it had saved a summary that slightly misrepresented what had actually been done. Not a lie — a compression. And a compression of configuration state is enough to break the next step. Verifying what it had stored, not just trusting the memory log, became a habit.
What clicked
Odín was not the first step in a planned programme of study. It was the moment that made studying feel necessary.
Before Odín, agentic AI was interesting in the abstract—worth watching, worth reading about. After Odín, it became a concrete question with concrete stakes: what does it actually take to make this work well? Not in a demo, not in a controlled environment, but with a real client, a real CRM, and a real standard of output.
That question did not have a short answer. It opened into harder ones: how do you structure knowledge so an agent can use it reliably? How do you know when it is doing what you asked, and when it is only appearing to?
Those are the questions this site and this work are built around. Odín was not the answer—it was the moment the questions became unavoidable. And the only way to answer them properly was to keep building, keep observing, and keep documenting what held and what did not.
The five minutes were not the result. The five minutes were the proof that the questions were worth asking.
Odín was the start. The case studies that came after are documented at build-your-agents.com.